Web Scraping Angel.co with Bot Protections
Illustrating how to overcome anti-bot system from angel.co
This post is educational only.
My intent to scrape Angel.co is to re-organize the information to create charts where I can spot trends and understand where the collective is going.
The existing website offers tools that will handle most of the use cases. For instance, you can sort the results by the number of companies, investors, followers, and jobs. Other than that, you cannot filter the results by the search.
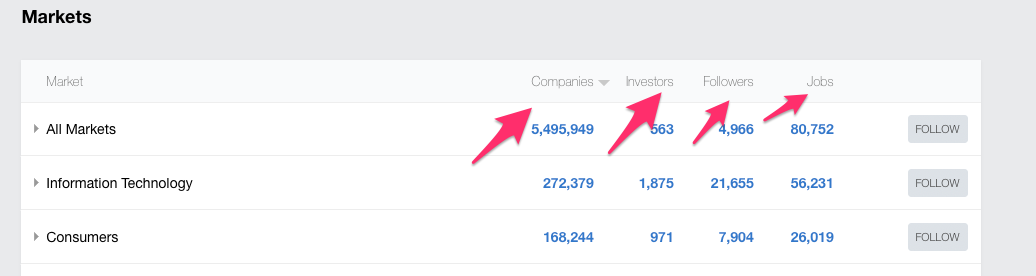
Also, Angel.co implemented some scraping protection by repeating specific categories twice. Even if you have the data, you are not sure if the data is unique or repeated.
I tried to scrape by using the Capybara-Selenium-Chrome-Webdriver combo, but it kicked the anti-bot system at the very first moment. My bot was facing CAPTCHA, and even after manually inputting the answers, the system knows it was a bot.
Then I had to find a different way to have the full index page. I tried saving the HTML, but it only keeps certain portions of the site.
I love challenges, so I thought there might be other ways to overcome this process.
I opened all categories manually so it would not trigger the anti-bot system. Then I open "Inspect" via Chrome. I copied the full-body tag and then pasted it into the original HTML file I saved previously. It worked. Now I can process the file separately.
Even though this is not an altogether web scraping technique, there is always a way to circumvent protection systems. Check out the video showing how I did it.